JEP 475: Late Barrier Expansion for G1
| Author | Roberto Castañeda Lozano & Erik Österlund |
| Owner | Roberto Castaneda Lozano |
| Type | Feature |
| Scope | Implementation |
| Status | Closed / Delivered |
| Release | 24 |
| Component | hotspot / compiler |
| Discussion | hotspot dash gc dash dev at openjdk dot org |
| Effort | M |
| Duration | M |
| Reviewed by | Thomas Schatzl, Vladimir Kozlov |
| Endorsed by | Vladimir Kozlov |
| Created | 2023/12/18 14:09 |
| Updated | 2025/01/28 08:42 |
| Issue | 8322295 |
Summary
Simplify the implementation of the G1 garbage collector's barriers, which record information about application memory accesses, by shifting their expansion from early in the C2 JIT's compilation pipeline to later.
Goals
-
Reduce the execution time of C2 when using the G1 collector.
-
Make G1 barriers comprehensible to HotSpot developers who lack a deep understanding of C2.
-
Guarantee that C2 preserves invariants about the relative ordering of memory accesses, safepoints, and barriers.
-
Preserve the quality of C2-generated code, in terms of both speed and size.
Non-Goals
- It is not a goal to retain G1's current early barrier expansion as a legacy mode. The switch to late barrier expansion should be fully transparent, except for the effect of lower C2 overhead, so such a mode is not necessary.
Motivation
The increasing popularity of cloud-based Java deployments has led to a stronger focus on reducing overall JVM overhead. JIT compilation is an effective technique for speeding up Java applications, but it incurs significant overhead in terms of processing time and memory usage. This overhead is particularly noticeable for optimizing JIT compilers such as the JDK's C2 compiler. Preliminary experiments show that expanding G1 barriers early, as is currently done, increases C2's overhead by around 10-20% depending on the application. This is not surprising, given that a G1 barrier is represented by more than 100 operations in C2’s intermediate representation (IR) and results in around 50 x64 instructions. Reducing this overhead is key to making the Java Platform a better fit for the cloud.
Another major contributor to JVM overhead is the garbage collector. As a semi-concurrent generational garbage collector (GC), G1 interfaces with the JIT compilers to instrument application memory accesses with barrier code. In the case of C2, maintaining and evolving this interface requires a deep knowledge of C2 internals, which few GC developers possess. Furthermore, some barrier optimizations require applying low-level transformations and techniques which cannot be expressed in C2's intermediate representation. These obstacles have slowed down or directly blocked the evolution and optimization of key aspects of G1. Decoupling G1 barrier instrumentation from C2 internals would enable GC developers to further optimize and reduce the overhead of G1, by means of both algorithmic improvements and low-level micro-optimizations.
C2 compiles Java methods to machine code using a sea of nodes IR. This IR is a type of program dependence graph that gives the compiler great freedom in scheduling machine instructions. While this simplifies and increases the scope of many optimizations, it makes it difficult to preserve invariants about the relative ordering of instructions. In the case of G1 barriers, this has resulted in complex bugs such as 8242115 and 8295066. We cannot guarantee the absence of other issues of a similar nature.
Early experiments and manual inspection of C2-generated code show that the instruction sequences generated by C2 to implement barriers are similar to the handwritten assembly code used by the bytecode interpreter to instrument memory accesses. This suggests that the scope for C2 to optimize barrier code is limited, and that code of similar quality could be generated if the barrier implementation details were hidden from C2 and expanded only at the end of the compilation pipeline.
Description
Early barrier expansion
Currently, when compiling a method, C2 co-mingles barrier operations together with the method's original operations in its sea-of-nodes IR. C2 expands the barrier operations for each memory access at the beginning of its compilation pipeline, when it parses bytecode into IR operations. Specific logic for G1 and C2 guides this expansion via the Heap Access API (JEP 304). Once the barriers are expanded, C2 transforms and optimizes all operations uniformly through its pipeline. This is depicted in the following diagram, where IR<C,P> denotes an IR that is specific to collector C and target operating-system/processor-architecture platform P:

Expanding GC barriers early in the compilation pipeline has two potential advantages:
-
The same GC barrier implementation, expressed as IR operations, can be reused for all platforms, and
-
C2 can optimize and transform the barrier operations across the scope of the entire method, potentially improving code quality.
However, there is limited practical benefit for two reasons:
-
Platform-specific G1 barrier implementations must be provided anyway for other execution modes, such as bytecode interpretation, and
-
G1 barrier operations are not very amenable to optimization due to control-flow density, memory-operation ordering constraints, and other factors.
The early expansion model has three tangible and significant disadvantages, already mentioned above: It imposes substantial C2 compilation overhead, it is opaque to GC developers, and it makes it difficult to guarantee the absence of barrier ordering issues.
Late barrier expansion
We therefore propose to expand G1 barriers as late as possible in C2's compilation pipeline, postponing it from bytecode parsing all the way to code emission, when IR operations are translated into machine code. This is depicted in the following diagram, using the same notation as above:
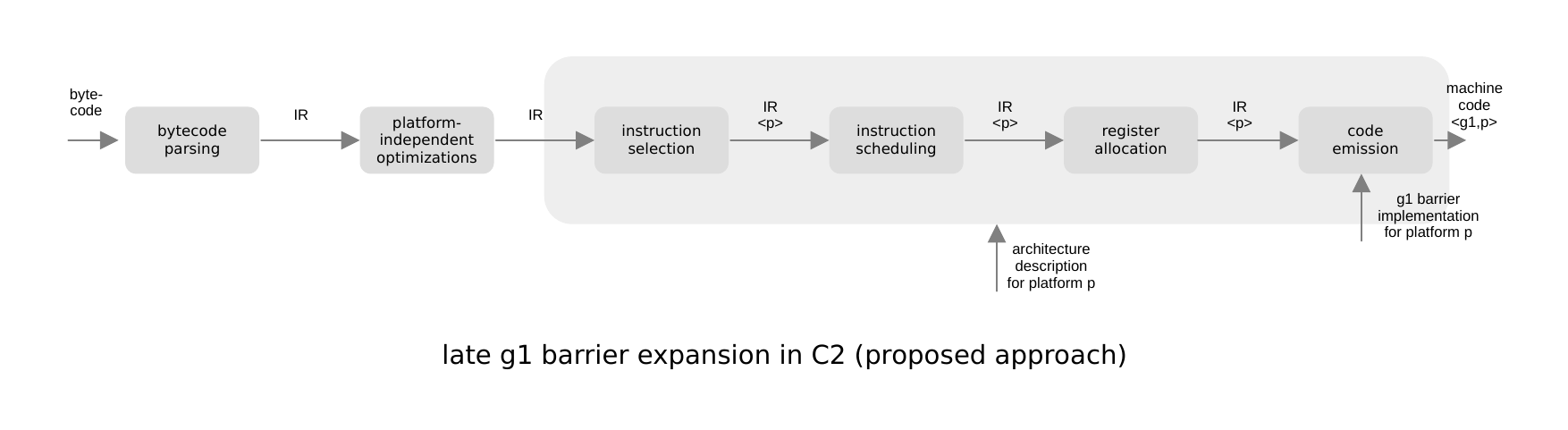
In detail, we implement late barrier expansion as follows:
-
IR memory accesses generated during bytecode parsing are tagged with the information required to generate their barriers code at code emission. This information is not exposed to C2's analysis and optimization mechanisms.
-
Instruction selection replaces abstract memory access operations with platform- and GC-specific instructions, but barriers are still implicit. GC-specific instructions are inserted at this point to, for example, make sure that the register allocator reserves sufficient temporary registers for barrier operations.
-
Finally, during code emission, each GC-specific memory access instruction is transformed into machine code according to its tagged barrier information. This code consists of the platform-specific memory instruction surrounded by barrier code. The barrier code is generated using the barrier implementation for the bytecode interpreter, augmented with assembly-stub routines that implement calls from the barrier into the JVM.
ZGC, an alternative fully-concurrent collector in the JDK, has used this design successfully since JDK 14. In fact, we saw late barrier expansion as a precondition for achieving the stability required for ZGC to be considered production-ready in JDK 15 (JEP 377).
For late barrier expansion in G1 we reuse many of the mechanisms developed for ZGC, such as extensions to the Heap Access API and logic to perform JVM calls in barrier code. We also reuse the assembly-level barrier implementations, which already exist for all platforms to support bytecode interpretation. These implementations are expressed in (pseudo) assembly code, which is a level of abstraction familiar to all HotSpot developers.
Candidate optimizations
Preliminary experiments show that a naive implementation of late barrier expansion, without any optimizations, already achieves quality close to that of C2-optimized code. Fully closing the performance gap, however, requires adopting some of the key optimizations that C2 currently applies. As part of this work, or possibly in follow-on work, we will re-evaluate these optimizations in the context of late barrier expansion and re-implement those which have a demonstrable performance benefit at the application level.
The optimizations that we consider focus on barriers for write operations, that is, operations of the form x.f = y, where x and y are objects and f is a field. Preliminary experiments show that these constitute around 99% of all executed G1 barriers. Write barriers consist of a pre barrier, to support concurrent marking, and a post barrier, to support the partition of heap regions into generations.
-
Remove barriers for writes into new objects — Writes into newly allocated objects do not require barriers, as long as there is no safepoint between the allocation and the writes. Currently, C2 removes write barriers eagerly when it detects this pattern. We can implement the same optimization for late barrier expansion by noting this situation in the information tagged to the write operation and then omitting the corresponding barrier code at code emission.
-
Simplify barriers based on nullness information — C2 can often guarantee that an object pointer to be stored in a memory write (
y) is either null or non-null. This can follow trivially from the original bytecode, or it can be inferred by C2's type analysis. Code emission can exploit this information to simplify or even remove post barriers, and to simplify object pointer compression and decompression when that mode is enabled.Currently, C2 implements such simplifications seamlessly via its generic platform-independent analysis and optimization mechanisms. We can implement the same simplifications for late barrier expansion by explicitly skipping the emission of unnecessary barrier and object pointer compression and decompression instructions according to the information provided by C2's type system. Preliminary experiments show that around 60% of executed write post-barriers can be simplified or removed by this technique.
-
Remove redundant decompression operations — When object pointer compression and decompression is enabled, a memory write stores a compressed pointer but the barriers operate on uncompressed pointers. Currently, C2's global analysis and optimization of a write and its barriers generally produces a single compression operation to make both versions of the object pointer available. A naive implementation of late barrier expansion produces both a compression and a decompression operation for each write. We can remove the redundant decompression operation by inserting compress-and-write pseudo-instructions matching pairs of compress and write IR operations. Within the scope of these pseudo-instructions we make both compressed and uncompressed versions of the object pointer available using a single compression operation, achieving the same effect as C2's current optimization.
-
Optimize barrier code layout — Both the pre barrier and the post barrier test whether the barrier is actually needed; if so, the barrier calls into the JVM to inform the collector of the write operation. Preliminary experiments, earlier investigations, and the original G1 paper show that barriers are infrequently needed in practice, hence a large fraction of barrier code is executed infrequently. Currently, C2 naturally places the infrequently-needed barrier code outside the main execution path, improving code cache efficiency. We can achieve the same effect for late barrier expansion by manually splitting the barrier implementation into frequent and infrequent parts, and expanding the latter in assembly stubs.
Alternatives
GC barriers can be expanded at several different points of the C2 compilation pipeline:
-
At bytecode parsing (early barrier expansion): GC barriers are expanded when initially constructing the IR.
-
After platform-independent optimizations: GC barriers are expanded after loop transformations, escape analysis, and so forth.
-
After instruction scheduling: GC barriers are expanded after platform-specific instructions are selected and scheduled, but before registers are allocated. (Today, there is no support for expansion at this level.)
-
After register allocation: GC barriers are expanded between register allocation and the final C2 transformations.
-
At code emission (late barrier expansion): GC barriers are expanded when IR instructions are translated into machine code.
Each of these points offers a different tradeoff in terms of C2 overhead, required C2 knowledge, risk of suffering instruction scheduling issues, and required platform-specific effort.
-
Generally, the later that barriers are expanded, the lower the C2 overhead. The largest savings are when barrier expansion is moved from bytecode parsing to after platform-independent optimizations, and then to after register allocation.
-
A developer working on any expansion point except code emission requires significant C2 knowledge.
-
Expanding barriers at bytecode parsing and after platform-independent optimizations does not require platform-specific support, but it does risk triggering instruction scheduling issues.
-
Expanding barriers at code emission, as proposed here, is the alternative with the lowest overhead and the only one that does not require C2-specific developer knowledge. As with all other platform-dependent expansion points, it shares the advantage of avoiding instruction scheduling issues and the disadvantage of requiring implementation effort for each platform.
The following table summarizes the advantages and disadvantages of each expansion point:
Expansion pointC2 overhead Requires C2 knowledge Control over scheduling Platform-independent At bytecode parsing (early) High Yes No Yes After platform-independent optimizations Medium Yes No Yes After instruction scheduling Medium Yes Yes No After register allocation Low Yes Yes No At code emission (late) Low No Yes No
Another dimension of the design space is the granularity of the barrier implementation exposed to C2. For ZGC, we experimented with representing barriers using a single IR operation in addition to the corresponding memory access operation, but concluded that even this coarser representation risks causing instruction scheduling issues. This conclusion is likely to apply to G1 as well, given the similarity of the scheduling issues for both collectors.
Testing
To mitigate the risk of introducing functional failures, we will combine
-
Regular testing based on the extensive, already-available JDK test suite executed under different configurations by Oracle's internal test system,
-
New tests to exercise cases that are not sufficiently covered today, and
-
Compiler and GC stress testing to exercise rare code paths and conditions that may otherwise be missed.
To mitigate the risk of performance regressions, we will evaluate the new implementation using a set of industry-standard Java benchmarks on different platforms.
To measure and compare compilation speed and code size, we will use the functionality provided by the HotSpot option -XX:+CITime. To control the variation in size and scope of the compiled methods across JVM runs, we will measure multiple iterations of each benchmark run and use JVM options such as -Xbatch to make each run more deterministic.
Risks and Assumptions
-
As with any change affecting the interaction of core JVM components — in this case, the G1 garbage collector and the C2 compiler — there is a non-negligible risk of introducing bugs that may cause failures and introduce performance regressions. To mitigate this risk, we will conduct internal code reviews and do extensive testing and benchmarking beyond the usual activities conducted for regular enhancements and bug fixes, as outlined above.
-
In the context of G1, imprecise card marking is an optimization that avoids multiple JVM calls for sequences of writes into different fields of the same object. The current implementation of this optimization, based on early barrier expansion, has not shown significant application-level performance benefits. We hence assume that we need not implement imprecise card marking for late barrier expansion in order to match the quality of currently generated code. Our work here might, however, enable a more profitable implementation of imprecise card marking in the future.